
Kubernetes Terminology
Values
In the following examples you will often see “.Values“ We have created /helm/values-tst.yaml that contain values for these parameters. This so we can have different parameters per environment.
An example:
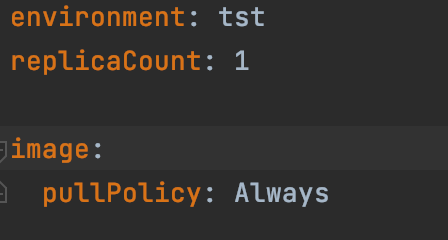
These would be accessed in other helm files like so:

Node
A worker or “computer“ that is running pods in the k8s cluster. Nodes have CPU and memory and can be added or removed from the cluster (to add processing power and memory). In our case the nodes were defined/allocated in terraform.
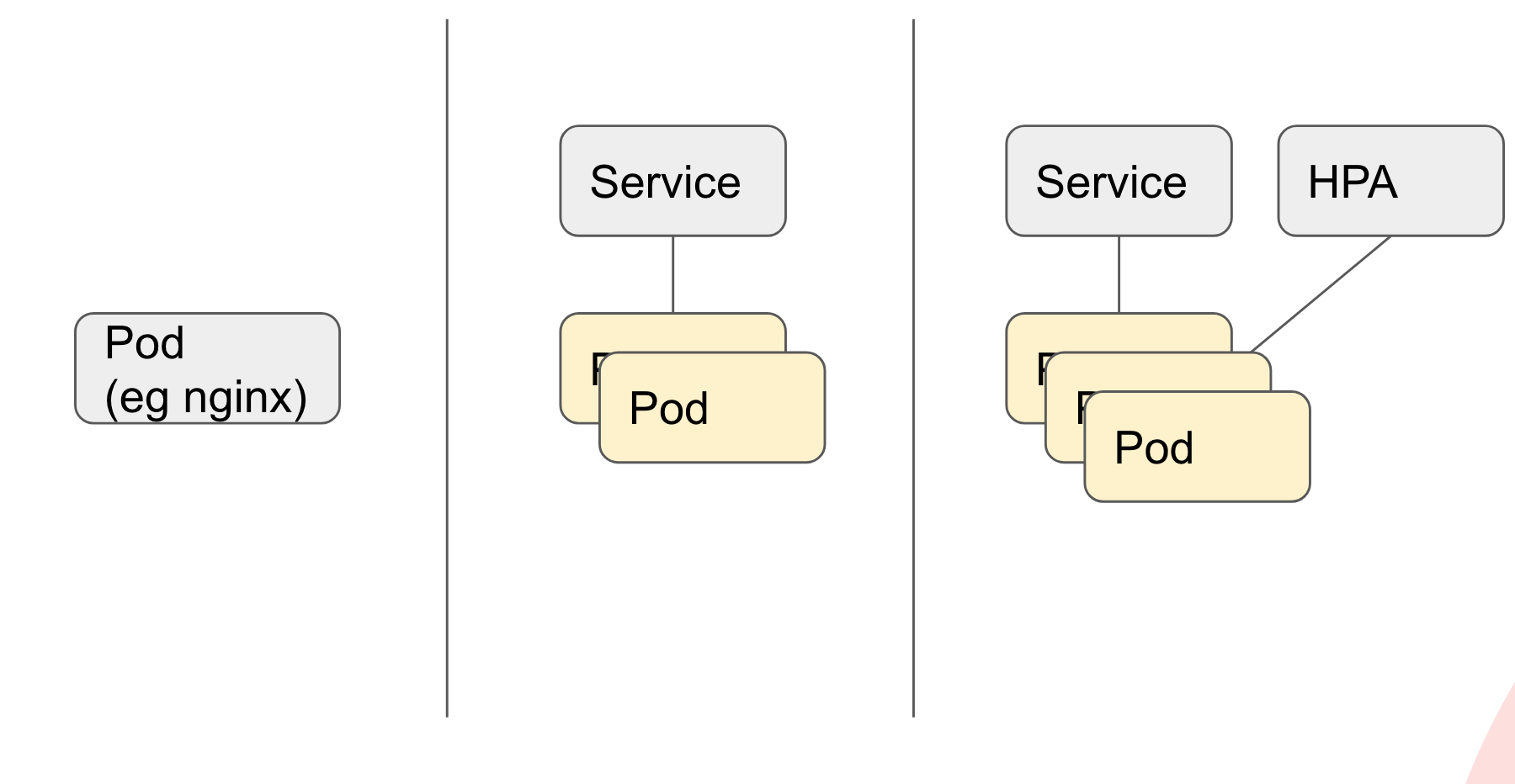
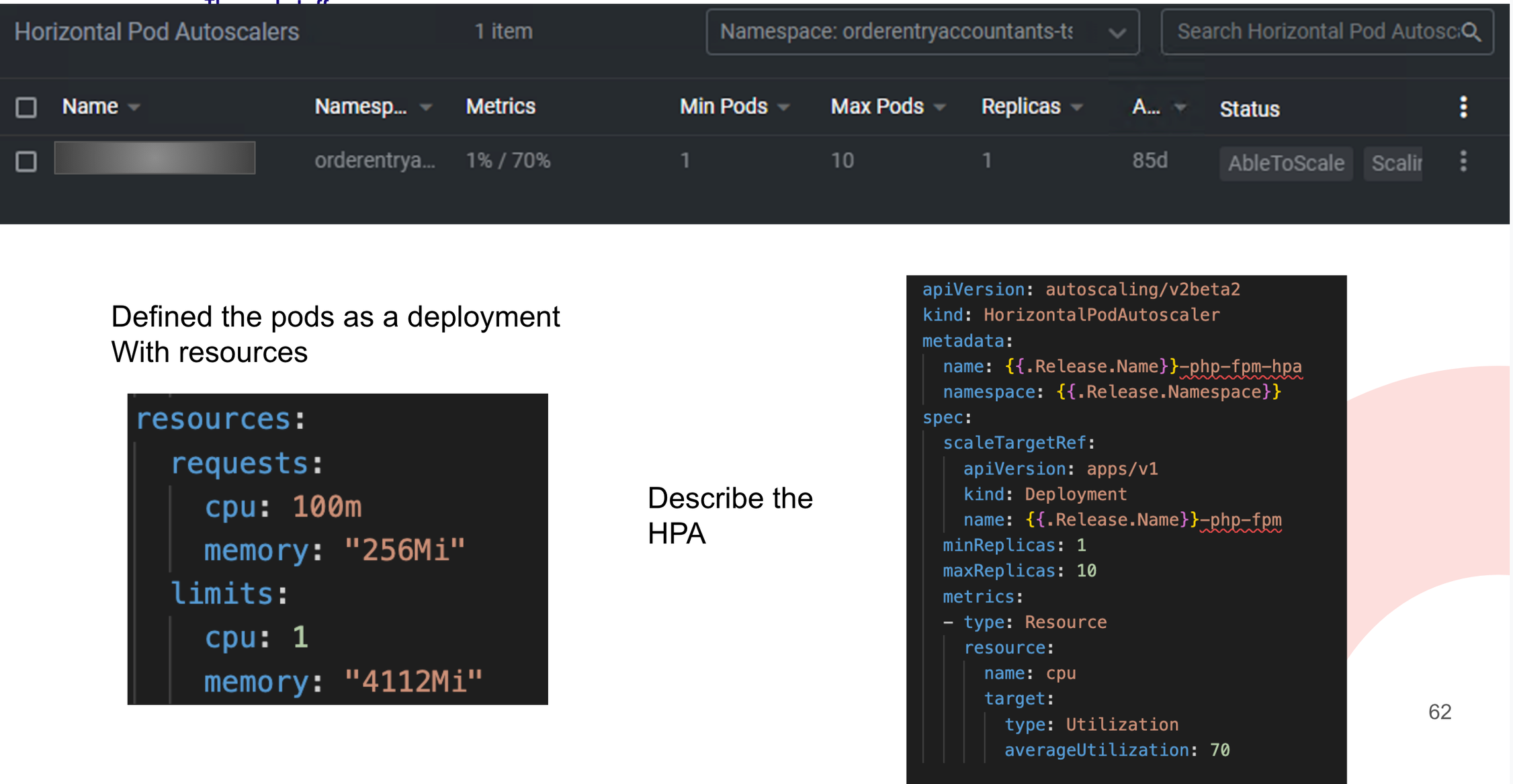
Pod / Service / HPA
A single Pod is an instance that typically is running a container. You can also have multiple containers in one pod (sometimes called sidecars). You can define a single pod in Helm, but that is not very practical.
By defining a Deployment, you can make sure when the container dies, it will automatically start another one, so there’s always something running. They will have other addresses. By using a service (eg. PHP), you can make sure calls to the backend always arrive on the pods in the deployment (curl PHP from the other instances will always lead to your pods in the deployment).
How awesome is autoscaling? With Horizontal Pod Autoscaling, you can configure that based on a resource limit (CPU or memory), the cluster can scale from X to Y pods. Both the scale-up and the cooldown are configurable.
Caveat: You need resource limits to be able to determine if you’re at 70%. Otherwise, K8s will just give you more CPU power (vertical scaling).
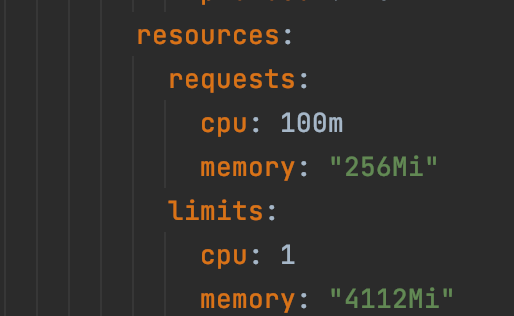
How cool is this!
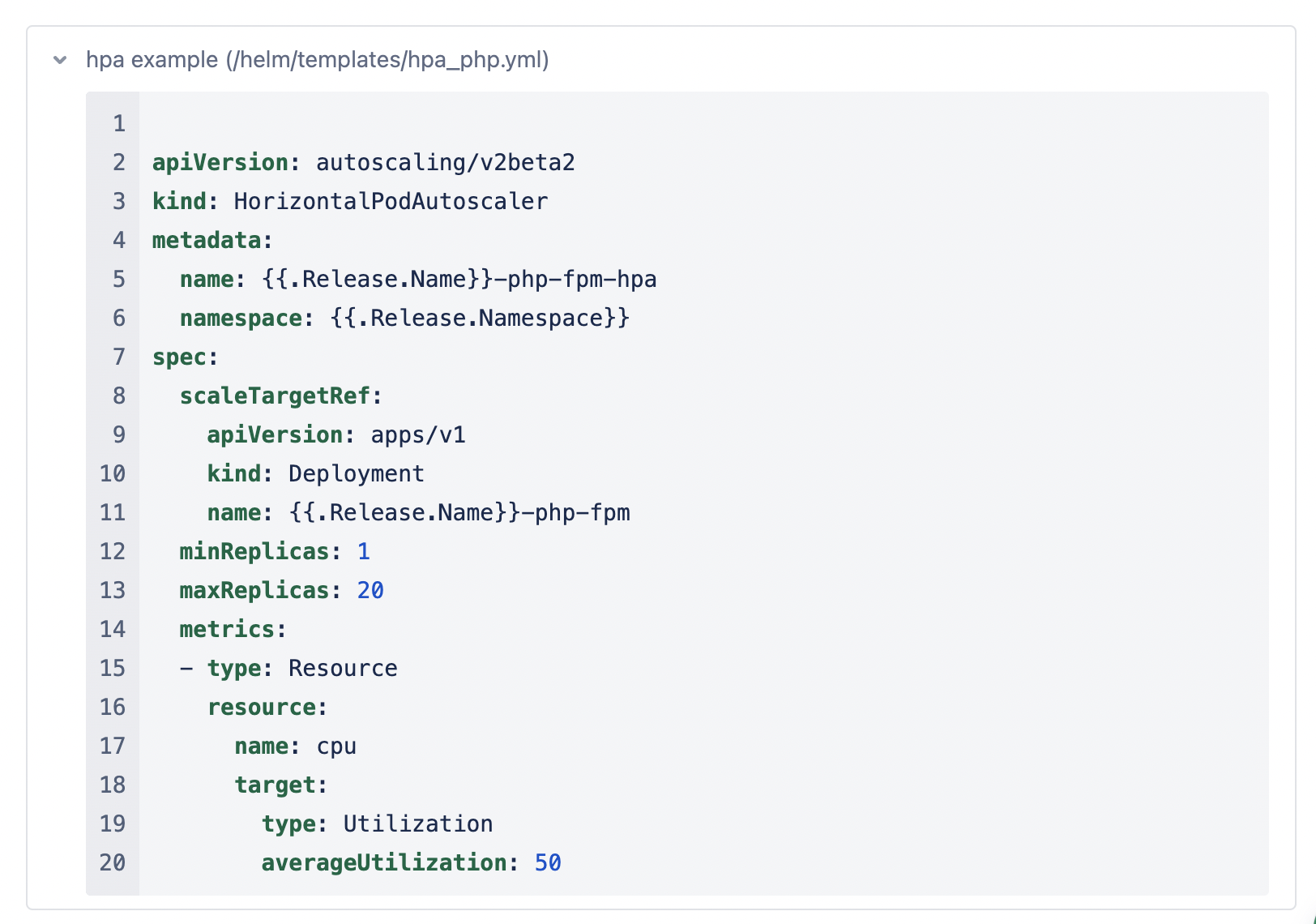
HorizontalPodAutoscaler
Deployment
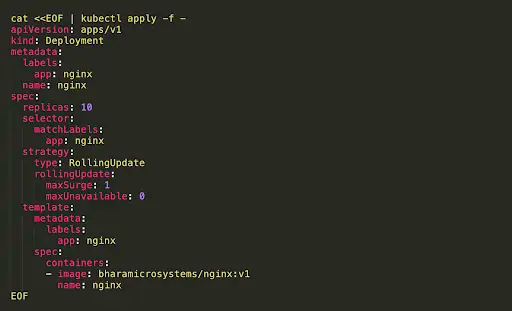
Since we’re doing fancy stuff now: Let's go to rolling deploys. A Deployment can be described in Helm too, and that will describe how to go from one version to another.
There’s multiple possibilities here.

- recreate: terminate the old version and release the new one
- ramped: release a new version on a rolling update fashion, one after the other
- blue/green: release a new version alongside the old version then switch traffic
- canary: release a new version to a subset of users, then proceed to a full rollout
- a/b testing: release a new version to a subset of users in a precise way (HTTP headers, cookie, weight, etc.). A/B testing is really a technique for making business decisions based on statistics but we will briefly describe the process. This doesn’t come out of the box with Kubernetes, it implies extra work to setup a more advanced infrastructure (Istio, Linkerd, Traefik, custom nginx/haproxy, etc).
More information on which is a good strategy can be found via this link.
For Drupal I would take in mind the following rule:
When you have schema updates: DO the Recreation, when you don’t you can choose any other strategy. In our case we will force everything to go down thus we will configure a rolling deploy (ramped) so that all non schema updating deploys will be deployed in a rolling manner.
What we do:
Drupal deployments with schema updates have a different deployment than the rolling deployment of frontend changes.
Schema changing deploys:
[We’re still working on this, but at the moment this is the way the customer wanted it.]
You will see in the deploy yaml (github action) that we will change the ingress to maintenance.
No traffic can reach our setup anymore. This makes sure no carts or forms are submitted during the schema changes.
After a successfull deploy the ingress is set back and the site is live with a New Schema.
Non schema changing deploys
with strategy: rollingUpdate you can make sure your system is never down and new containers are spun up and gradually receive traffic.
PersistentVolumeClaim (PVC)
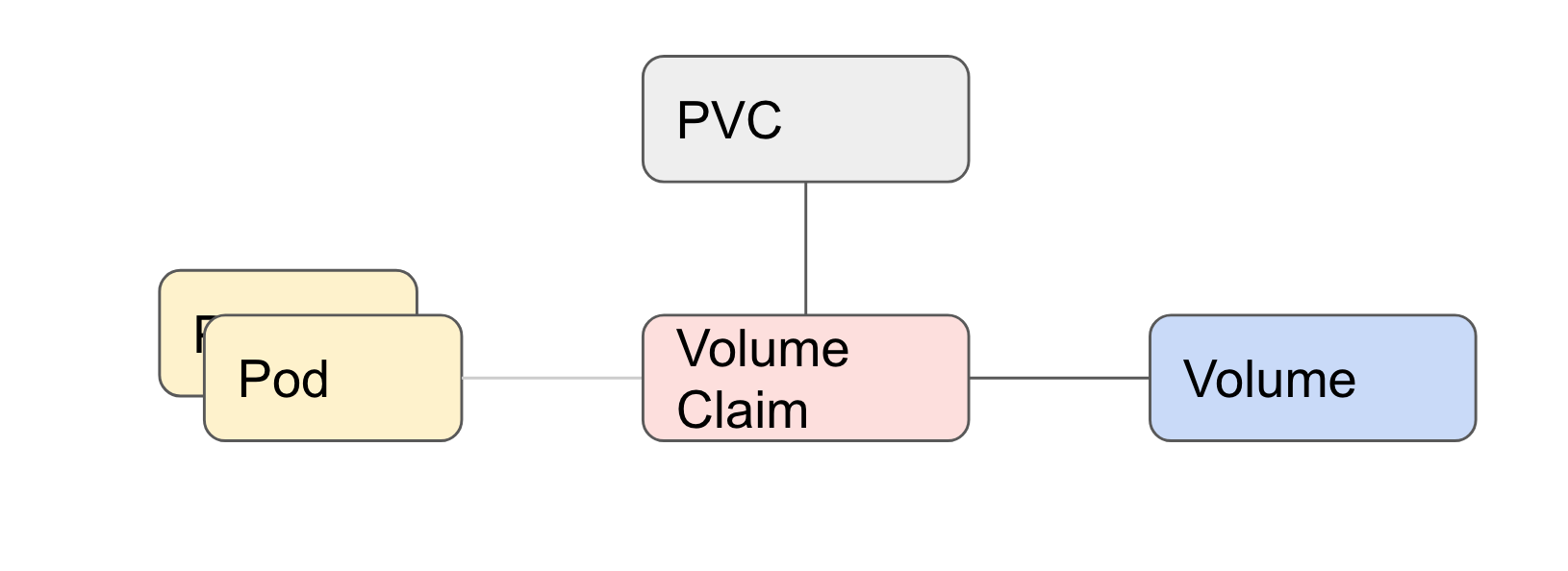
Since we’re scaling horizontally, we’ll need to abstract the storage away.
Drupal has three places of storage
- /tmp
- private files
- public files
What we’ve done is in terraform created these 3 volumes for every project.
Every container will then mount this.
To make this work in Helm you need:
- Add the columeMounts to the container
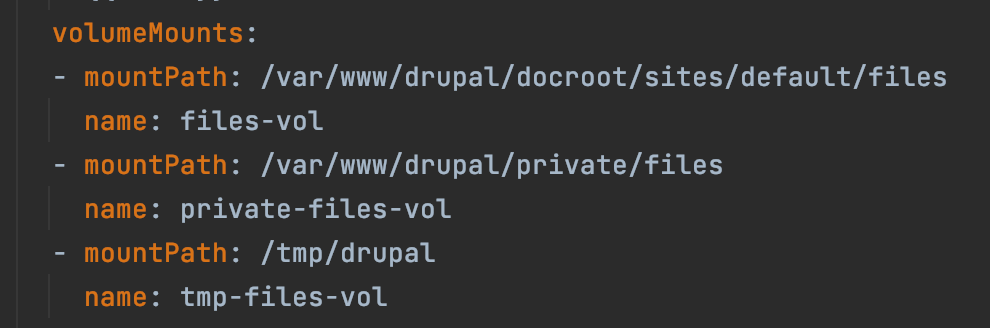 columeMounts to the container
columeMounts to the container - Add the volumes to the spec
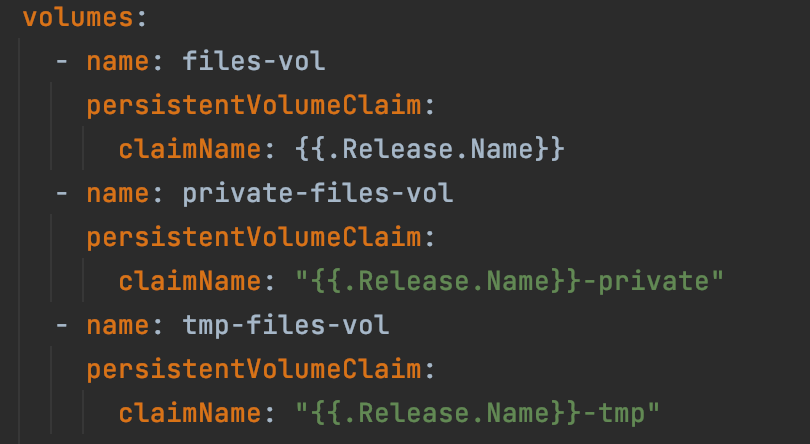 volumes to the spec
volumes to the spec
This is applicable for PHP deployment, Nginx (needs the assets too) Cron Drush container (if you like that)
Configmap
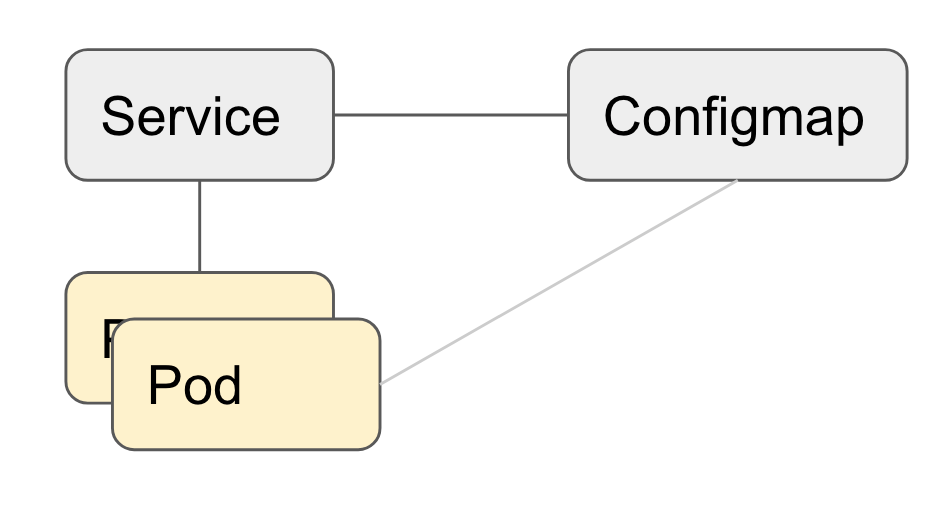
In helm we also define configmap. This allows us to work with contributed images (eg. the varnish container) and just add configration to that container. In the Varnish configmap we add the default.vcl that is used for this project. Every container of this type that is spun up will then also have this configuration.
The example Configmap Dynamically loads the vcl file. This allows us to have the default.vcl in our repo, and it will deploy into the Varnish container.
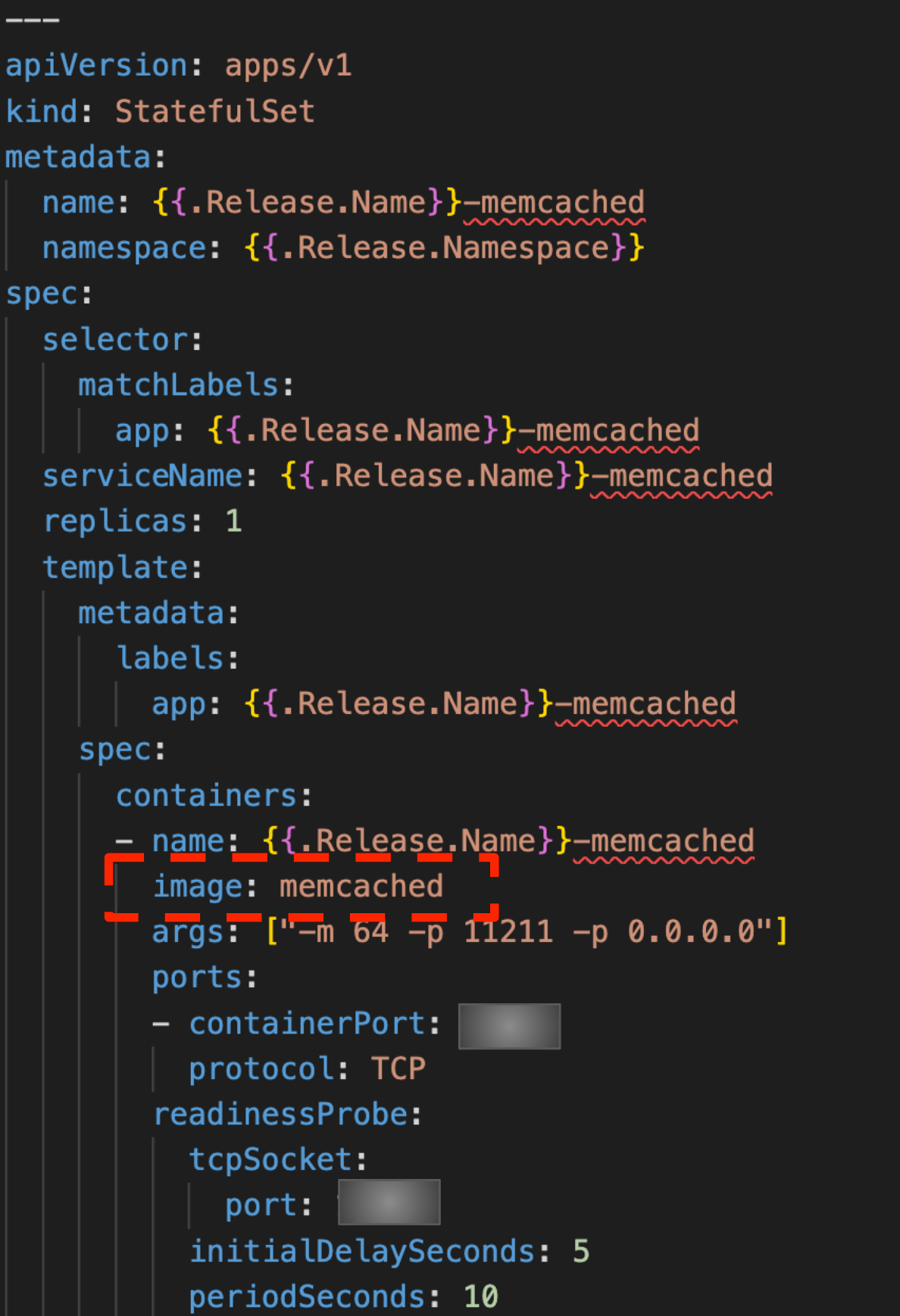
Statefullset
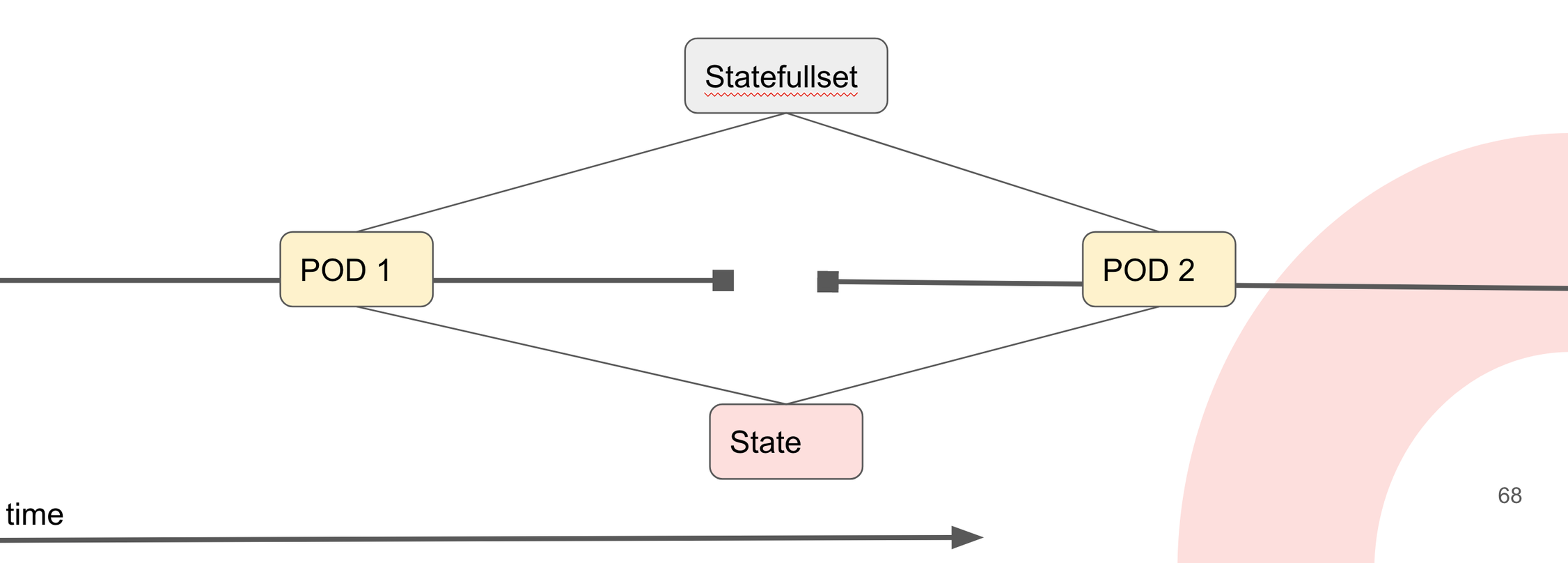
Sometimes you want the state to be saved. This is the case for example with memcache.In the graph above you see that we can spin up a new memcache container but it whould have the saved state.
kind: Statefullset
You could also do this with a Deployment and mounted volumes. But In Kubernetes they defined this as a Statefullset.
Statefullsets differ from deployments in that they maintain sticky identities for each pod. Pods may be created from an identical spec, but they are not interchangeable and are thus assigned unique identifiers that persist through rescheduling. Typically in a deployment, the replicas all share a volume and PVC, while in a Statefulset each pod has its own volume and PVC.
in this example we’re using the contributed memcached image.

Job
A kubernetes Job can be defined in Helm. You could use this to run one-off tasks in a pod.
The job will instantiate a pod, and then when the container is done with the task, the job is done. We started with doing deploys in k8s Jobs, but went away from this (different policies between environments made the behavior not always the same).
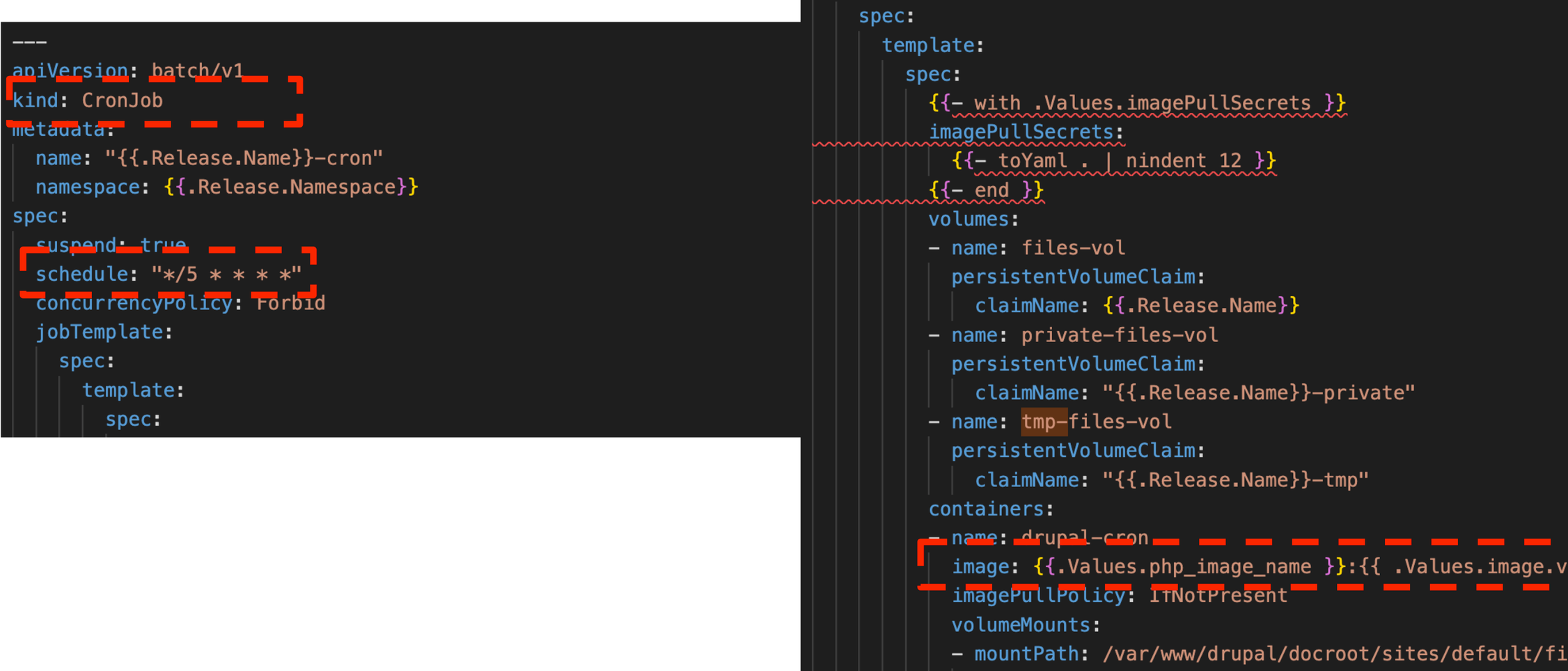
Cronjob
In K8s you can define cronjobs. Every X time, a job will be fired. The task will run in a container I (isolated) and not harm the performance of the Webservers doing application work. The only downside to this approach: every pod is monitored separately in new relic and thus to see cron performance it’s hard to compare. We’re looking at Dynatrace, but that’s ongoing.
Ingress
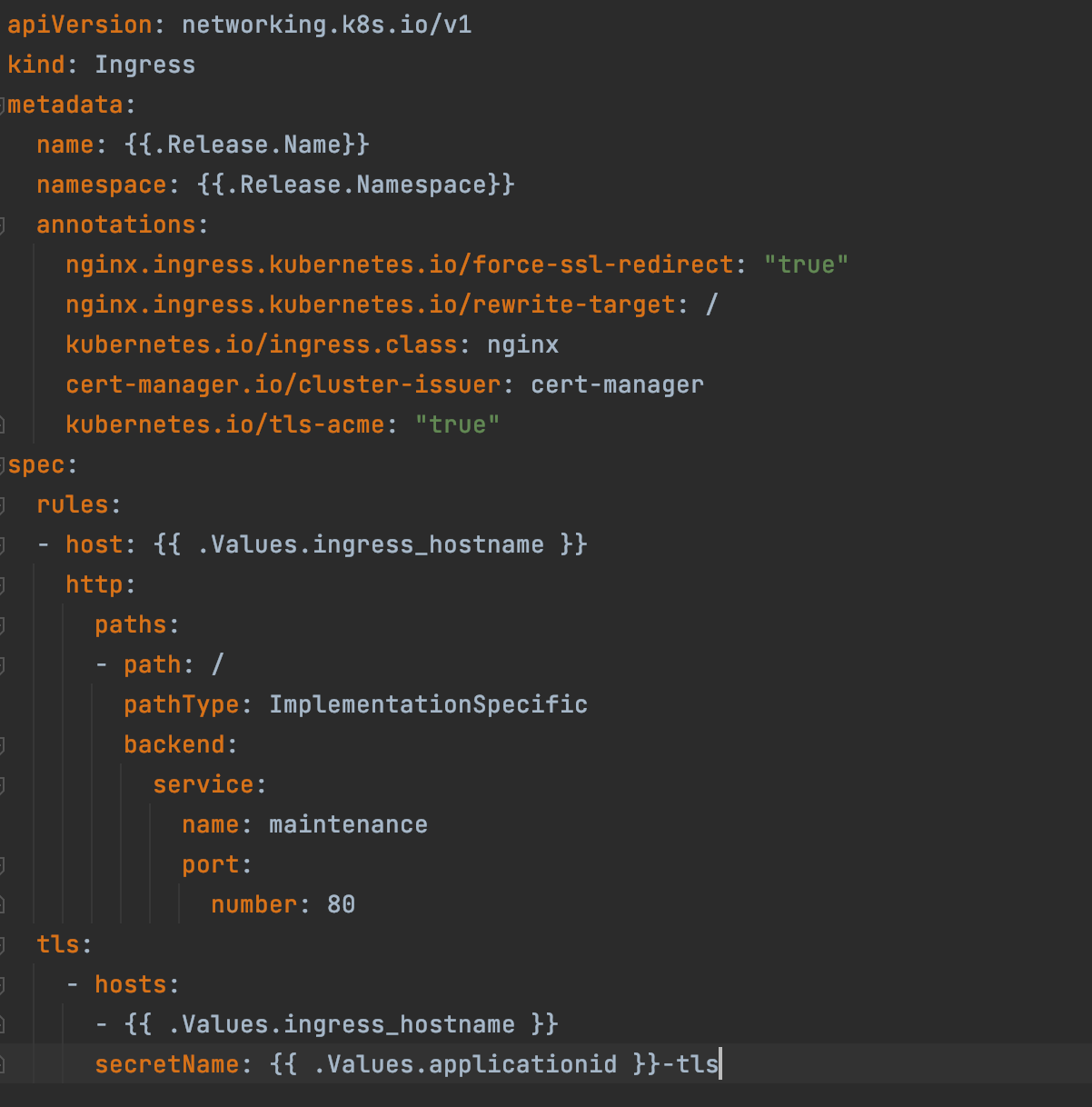
With ingress we can define where traffic is routed. We have only one ingress and as you see by default it’s maintenance. Because immediately after deploy we do the schema updates and only when that succeeded we will change the ingress in a github action to “name: varnish”.
Loadtesting with K6
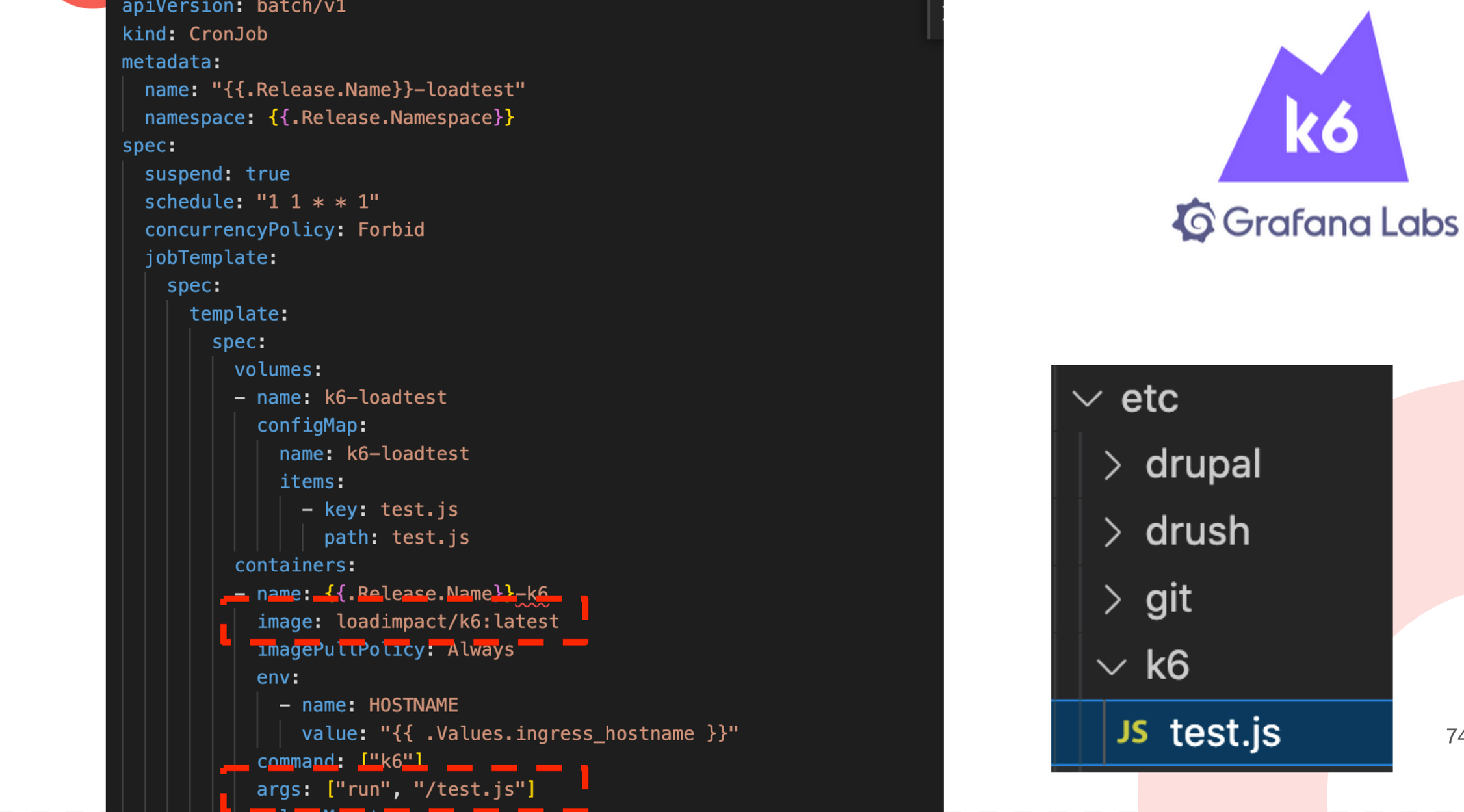
For loadtests we’re using the provided k6 image with a configmap that loads a test.js. I also created the k6 image as a cronjob that is suspended (paused) by default. This way you can just trigger the cronjob once and it will run the loadtests for you. I added this trigger too as a github action. This way we could have full control over when to run loadtests.
Monitoring - Newrelic
Monitoring this all is a little harder than monitoring a single server.
Monitoring is also a metier on its own.
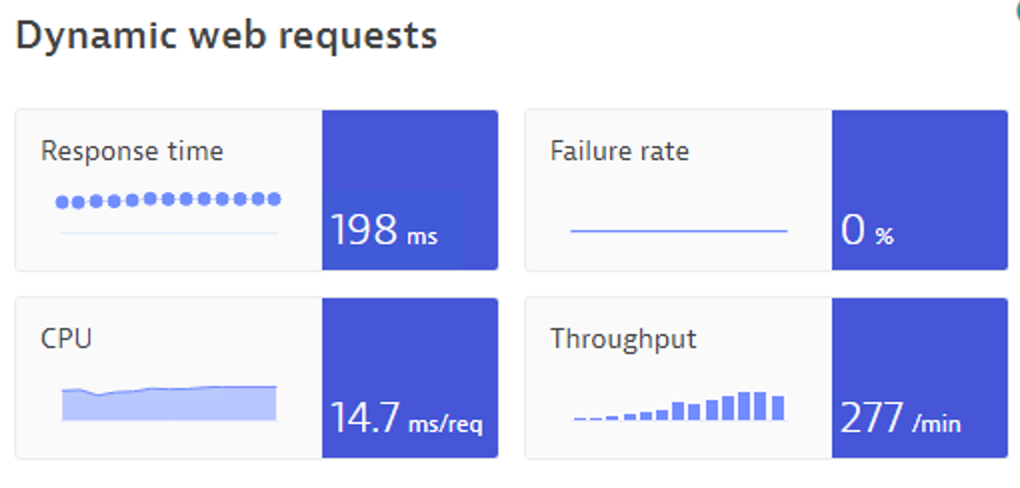
We started with Newrelic. To achieve this, we added the Newrelic agent to our docker base images.

After this we started the agent container and data was streaming in.
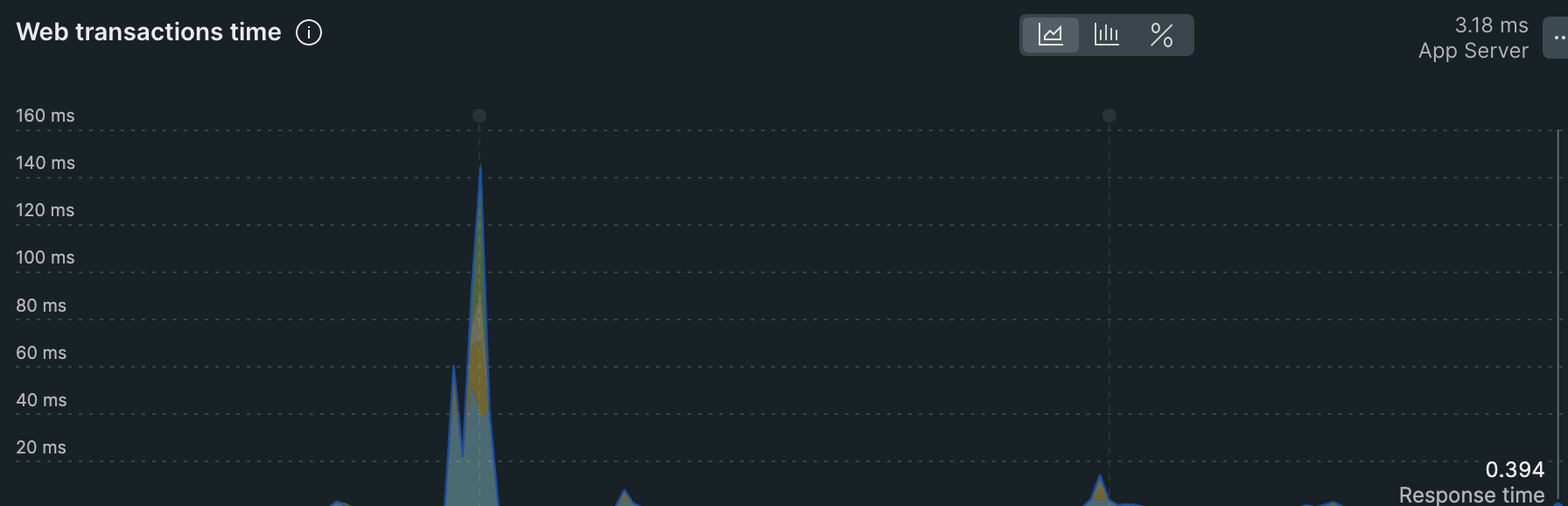
Monitoring - prometheus
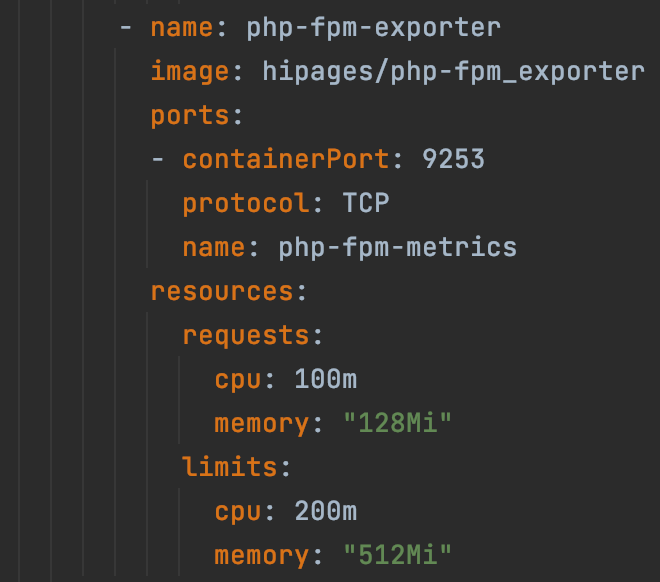
We also wanted data to stream to prometheus, so we configured these sidecars. (that’s what they call it) The PHP fpm exporter exports telemetry. I have not seen the output of this yet.
Monitoring - Dynatrace
I don’t have much experience with Dynatrace, so can’t tell much about this yet. We also configured Dynatrace as INIT containers. They slowdown the bootup of pods and thus impact the autoscaling. This is not ideal. This is something for a separate blogpost.
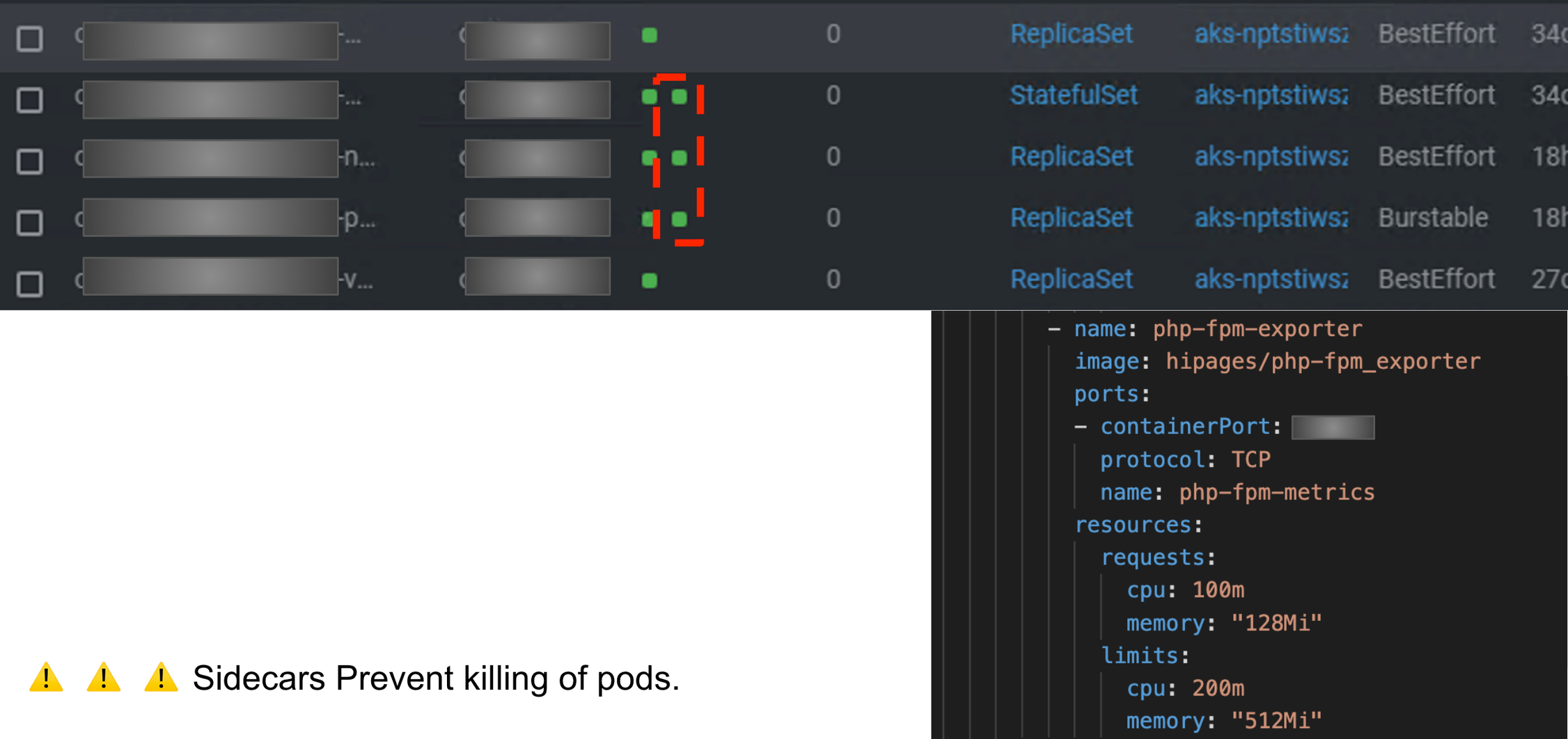
Sidecars issue
Cronjob creates a new job that spins up a PHP container and the monitoring. The PHP is ready the monitoring was still there, disabling the end of the job. We bumped into this but, in the end disabled the fpm exporter for cronjobs.


