
We all use searches multiple times a day without ever giving them a second thought. Browsing a webshop to find that one particular product, searching through forums to find a solution to your specific problem, or filtering stores based on your location to find the closest one, etc.
All of these examples require the same thing: content that is indexed in such a way that it can be filtered. In general, this is quite easy to set up: all you need is a database and a query to get you started.
However, what should you do if your visitors are more demanding and expect to be fed the right content when searching for plurals or a combination of words or synonyms? In the majority of cases, such complex queries fall beyond the reach of default search solutions, leading to dreaded messages like ‘Your search yielded no results’. This very quickly leads to user frustration and, subsequently, fewer conversions on your website. And this is only the start of it… What if your website also serves Germanic languages other than English? Suddenly, you are confronted with concatenations of words such as the infamous ‘Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz’ or ‘Chronischevermoeidheidssyndroom’.
In this blog post, we explain how you can configure Apache Solr to improve your multilingual content indexing and querying. We will shed some light on the ways indexing and querying is configured and can be tested, so you can make sure that Solr can understand your content and return a better result when users are searching through it. We will be using Dutch as an example, because of its compound word complexity. The underlying principles, however, are valid in plenty of use cases for other languages and search-related problems.
What are compound words?
First things first: let’s analyze our definitions. If we stick with the example of ‘chronischevermoeidheidssyndroom’. This word consists of multiple building blocks: the adjectives ‘Chronische’ and ‘vermoeidheid’ and the noun ‘syndroom’. In Dutch, it is perfectly acceptable to combine these elements into one long noun - and the exact same principle applies to German. In English, the direct translation looks very similar: ‘Chronic Fatigue Syndrome’. The only difference, of course, is those handy spaces in between the individual components! Most language processing tools split words by spaces, which makes it easy to search for parts of a search term, as they already appear split up in the text. In the case of the German and Dutch examples above, this isn’t so easy to do. Because of this added complexity, we will need to configure our language processing tool to understand what the possible compound words are and how they are combined. Luckily, there are certain grammar tools around that make it possible to tackle this added complexity through handy algorithms!
Getting started
First of all, we must make sure to install the necessary modules:
- https://www.drupal.org/project/search_api
- https://www.drupal.org/project/search_api_Solr
- https://www.drupal.org/project/search_api_solr_multilingual (optional)
The Search API acts as a bridge between different search servers and the Search API Solr allows to communicate with a Solr server.
Once those modules have been installed, the most important one for multilingual sites is the Search API Solr Multilingual module. This module allows to connect with a Solr server with better support for non-English languages.
If you are using the 8.2.x branch of Search API Solr, you won’t have to download the multilingual module, as it is merged into the Search API Solr module.
Once these modules have been installed, you will be able to set up a connection to a Solr server using the Multilingual backend connector. We will not go any deeper into the whole installation process, as the modules all come with their own detailed installation instructions.
Configuring your Solr server for multilingual content
The multilingual Solr module also provides a download mechanism that generates the Solr configuration files that are needed to support multilingual content indexation.
One of the most important files in this configuration is the schema_extra_types.xml file.
<!--
Dutch Text Field
5.0.0
-->
<fieldType name="text_nl" class="Solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<charFilter class="Solr.MappingCharFilterFactory" mapping="accents_nl.txt"/>
<tokenizer class="Solr.WhitespaceTokenizerFactory"/>
<filter class="Solr.WordDelimiterFilterFactory" catenateNumbers="1" generateNumberParts="1" protected="protwords_nl.txt" splitOnCaseChange="0" generateWordParts="1" preserveOriginal="1" catenateAll="0" catenateWords="1"/>
<filter class="Solr.LengthFilterFactory" min="2" max="100"/>
<filter class="Solr.LowerCaseFilterFactory"/>
<filter class="Solr.DictionaryCompoundWordTokenFilterFactory" dictionary="nouns_nl.txt" minWordSize="5" minSubwordSize="4" maxSubwordSize="15" onlyLongestMatch=""/>
<filter class="Solr.StopFilterFactory" ignoreCase="1" words="stopwords_nl.txt"/>
<filter class="Solr.SnowballPorterFilterFactory" language="Kp" protected="protwords_nl.txt"/>
<filter class="Solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<charFilter class="Solr.MappingCharFilterFactory" mapping="accents_nl.txt"/>
<tokenizer class="Solr.WhitespaceTokenizerFactory"/>
<filter class="Solr.WordDelimiterFilterFactory" catenateNumbers="0" generateNumberParts="1" protected="protwords_nl.txt" splitOnCaseChange="0" generateWordParts="1" preserveOriginal="1" catenateAll="0" catenateWords="0"/>
<filter class="Solr.LengthFilterFactory" min="2" max="100"/>
<filter class="Solr.LowerCaseFilterFactory"/>
<filter class="Solr.SynonymFilterFactory" synonyms="synonyms_nl.txt" expand="1" ignoreCase="1"/>
<filter class="Solr.StopFilterFactory" ignoreCase="1" words="stopwords_nl.txt"/>
<filter class="Solr.SnowballPorterFilterFactory" language="Kp" protected="protwords_nl.txt"/>
<filter class="Solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
This file declares a field type called text_nl, which has some filters declared when indexing the content and some when performing a query on the index. Some names speak for themselves, for example:
- MappingCharFilterFactory: this uses the accents_nl.txt file to map a certain character to another. Using this, we can filter out special characters. This means that the search mechanism can still understand what you’re looking for if you search without using this special character.
- CharacterWhitespaceTokenizerFactory: this tokenizer splits words based on whitespace characters - this way each word get indexed.
- LengthFilterFactory: Filters out words based on the max and min values. Example: min=2, max=100 will filter out words that are less than 2 characters and longer than 100 characters.
- LowerCaseFilterFactory: makes the token lower case.
- StopFilterFactory: Filters out words which are mentioned in the stopwords.txt file attached to this filter. This list contains words with no added value, like eg. but, for, such, this or with.
- SnowballPorterFilterFactory: The most important argument for this factory is the language argument, as this will define how the stem of a certain word is defined. As you can see in the example, we are using Kp and not NL for Dutch stemming. This is because the Kp stemmer better stems Dutch words. Want to know more about this algorithm? You can find all the details via this link.
In short, this filter will result in plural words being indexed together with the stem of the word. E.g. 'modules' → 'modules', 'module' - RemoveDuplicatesTokenFilterFactory: removes any duplicate token.
Some filters are more complex, so let’s explain them more in-depth:
- WordDelimiterFilterFactory: this filter will split words based on the arguments.
- CatenateNumbers: If non-zero number parts will be joined: '2018-04' →'201804'.
- GenerateNumberParts: If non-zero it splits numeric strings at delimiters ('2018-04' → '2018', '04'.
- SplitOnCaseChange: If zero then words are not split on CamelCase changes. Example: 'splitOnCaseChange' → 'split', 'On', 'Case', 'Change'.
- GenerateWordParts: If non-zero words are splitted at delimiters. 'DrupalCon' → 'Drupal', 'Con'.
- PreserveOriginal: if non-zero the original entry is preserved. 'DrupalCon' → 'DrupalCon', 'Drupal', 'Con'.
- CatenateAll: If non zero words and number parts will be concatenated. 'DrupalCon-2018' → 'DrupalCon2018'
- CatenateWords: If non zero word parts will be joined: 'high-resolution-image' → 'highresolutionimage'
- Protected: the path to a file that contains a list of words that are protected from splitting.
- DictionaryCompoundWordTokenFilterFactory: this filter splits up concatenated words into separate words based on the list of words given as dictionary argument. Example: 'flagpole' → 'flag', 'pole'
- SynonymFilterFactory: This filter allows to define words as synonyms by passing along a list of synonyms as synonyms argument. This list is a comma separated list of words which are synonyms. This can also be used to solve spelling mistakes.
- Example: drupal, durpal - Will make sure that when a user searches for durpal, results with drupal indexed will be returned as possible matches.
With this setup, you should be able to make your search indexing and querying a lot smarter. You can find different synonyms.txt, nouns.txt and accent.txt files if you search the web for your language.
Where can I find these txt files?
Remember the section about the compound words? This is where this knowledge comes in handy. We spent a long time browsing the web to find a good list of compound words and stop words. To make your life easier, we’ve attached them to this blog post as GitLab links for you to see, edit and collaborate on. These files are for Solr version 5 and above and are for the Dutch, English & French language.
Pay attention, however! When adding these files to an existing index, you will need to use a multilingual server connection and then reindex your data. If you don’t do this, your index and query will no longer be in sync and this might even have a negative impact on your environment.
Testing indexed and query results
When you have installed a Solr server and core, you can visit the Solr dashboard. By default, this can be reached on localhost:8983/
If you select your core, you will be able to go to the Analysis tab.
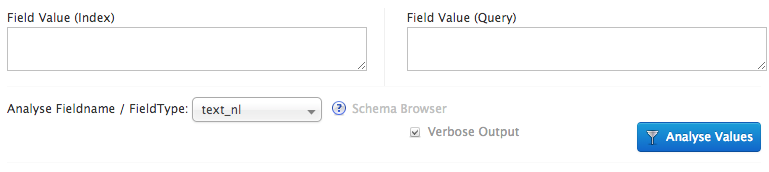
This screen allows to perform a search and see how the index (left input) or the query (right input) will handle your value. It’s important to select the field type, so the analysis knows what filters it needs to use on your value.
Things to avoid
Let’s stick with our example of the Dutch word ‘Chronischevermoeidheidssyndroom’ and see how the index will handle this word. If you don’t configure Apache Solr with support for Dutch, it will only store ‘chronischevermoeidheidssyndroom’ in the index. If someone were to look for all kinds of ‘syndromes’, this item wouldn’t show up in the website’s results. Perhaps you would expect otherwise, but Apache Solr isn’t that smart.
What you do want to happen
However, if the index is configured correctly with support for Dutch words, it will return the following results:
Name of filter | ||||
|---|---|---|---|---|
MappingCharFilterFactory | C|h|r|o|n|i|s|c|h|e|v|e|r|m|o|e|i|d|h|e|i|d|s|s|y|n|d|r|o|o|m | |||
WhitespaceTokenizerFactory | Chronischevermoeidheidssyndroom | |||
LengthFilterFactory | Chronischevermoeidheidssyndroom | |||
LowerCaseFilterFactory | chronischevermoeidheidssyndroom | |||
DictionaryCompoundWordTokenFilterFactory | “chronischevermoeidheidssyndroom”, “chronisch”, “chronische”, “scheve”, “vermoeid”, “vermoeidheid”, “syndroom”, “droom”, “room” | |||
StopFilterFactory | “chronischevermoeidheidssyndroom”, “chronisch”, “chronische”, “scheve”, “vermoeid”, “vermoeidheid”, “syndroom”, “droom”, “room” | |||
SnowballPortretFilterFactory | “chronischevermoeidheidssyndroom”, “chronisch”, “chronische”, “scheve”, “vermoeid”, “vermoeidheid”, “syndroom”, “droom”, “room” | |||
RemoveDuplicatesTokenFilterFactory | “chronischevermoeidheidssyndroom”, “chronisch”, “scheve”, “vermoeid”, “syndroom”, “droom”, “room” | |||
The word ‘Chronischevermoeidheidssyndroom’ will eventually be indexed with the following result: ‘chronischevermoeidheidssyndroom’, ‘chronisch’, ‘scheve’, ‘vermoeid’, “‘syndroom’, ‘droom’, ‘room’. If somebody searches for any of these words, this item will be marked as a possible result.
If, for example, we run a search for ‘Vermoeidheid’, we should expect that our beloved ‘Chronischevermoeidheidssyndroom’ pops up as a result. Let’s try this out with the Solr analysis tool:
MappingCharFilterFactory | V|e|r|m|o|e|i|d|h|e|i|d |
WhitespaceTokenizerFactory | Vermoeidheid |
WordDelimiterFilterFactory | Vermoeidheid |
LengthFilterFactory | Vermoeidheid |
LowerCaseFilterFactory | vermoeidheid |
SynonymFilterFactory | vermoeidheid |
StopFilterFactory | vermoeid |
SnowballPortretFilterFactory | vermoeid |
RemoveDuplicatesTokenFilterFactory | vermoeid |
Eventually, our query will search for items indexed with the word ‘vermoeid’, which is also a token index when indexing the word 'Chronischevermoeidheidssyndroom'.
In short
When up a Solr core for multilingual content, it’s important that we provide extra field types that handle the text in the correct language. This way, Solr can index the word in such a way that plurals and concatenations of words are understood. This, in turn, provides a better experience to the user who is looking for a certain piece of content. With everything configured correctly, a user running a search for ‘syndroom’ will be served all compound words as a possible result, providing the user a better overview of your site’s content.
You can find our Dropsolid resources here: https://gitlab.com/dropsolid/multilingual-solr-config